Semantic Amodal Instance Level Video Object Segmentation -- A Synthetic Dataset and Baselines
Yuan-Ting Hu, Hong-Shuo Chen, Kexin Hui, Jia-Bin Huang, Alexander G. Schwing
SAIL-VOS 3D, a dataset with frame-by-frame mesh annotations which extends SAIL-VOS is now available! See the website [here].
The SAIL-VOS (Semantic Amodal Instance Level Video Object Segmentation) is a dataset aiming to stimulate semantic amodal segmentation research.
Humans can effortlessly recognize partially occluded objects and reliably estimate their spatial extent beyond the visible. However, few modern computer vision techniques are capable of reasoning about occluded parts of an object. This is partly due to the fact that very few image datasets and no video dataset exist which permit development of those methods. To address this issue, we present the SAIL-VOS dataset, a synthetic dataset extracted from the photo-realistic game GTA-V.
Video
Dataset Statistics
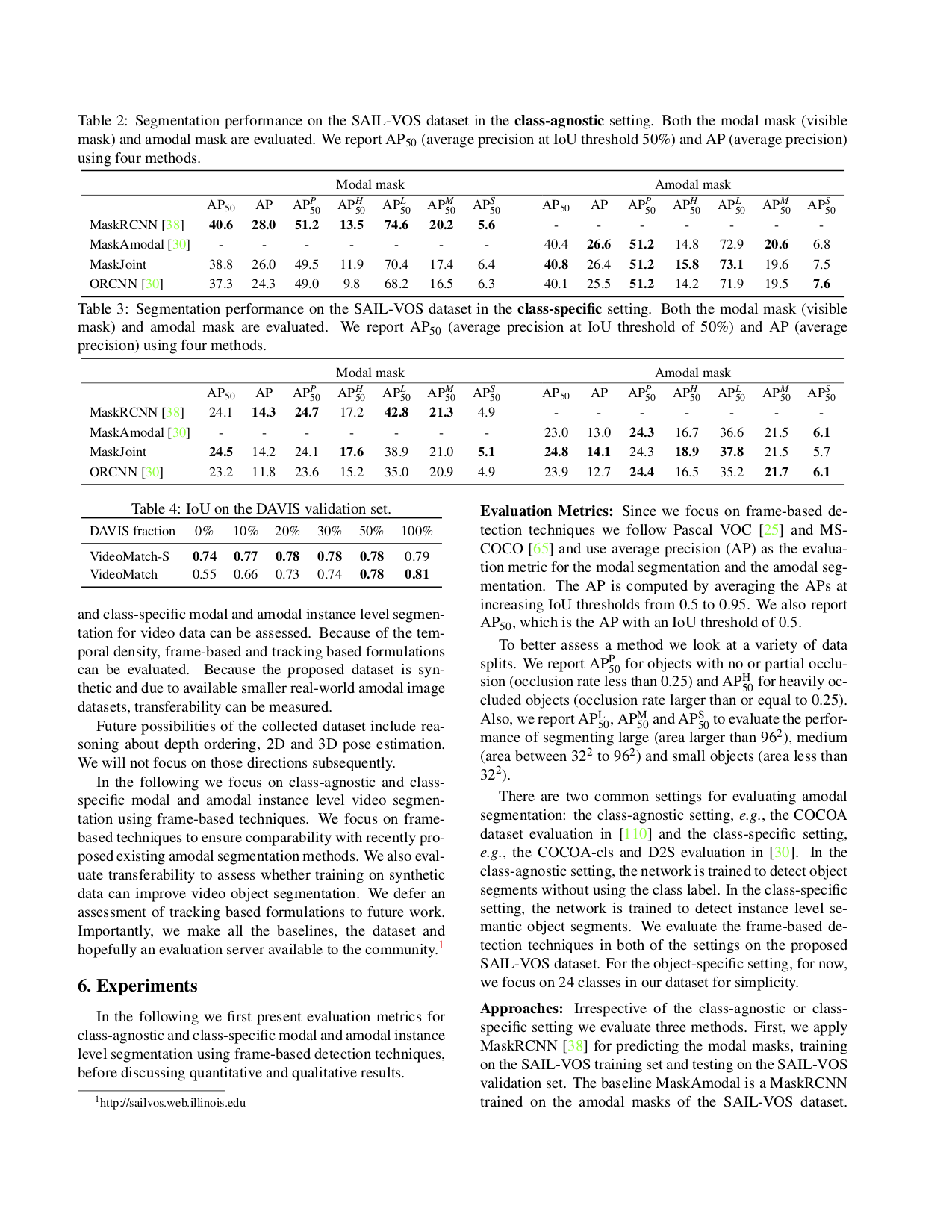
The SAIL-VOS dataset contains in total 201 video sequences and 111,654 frames. The training set contains 160 video sequences (84,781 images, 1,388,389 objects) while the validation set contains 41 video sequences (26,873 images, 507,906 objects). In addition to the training and validation set, we retain a test-dev set and a test-challenge set for future use.
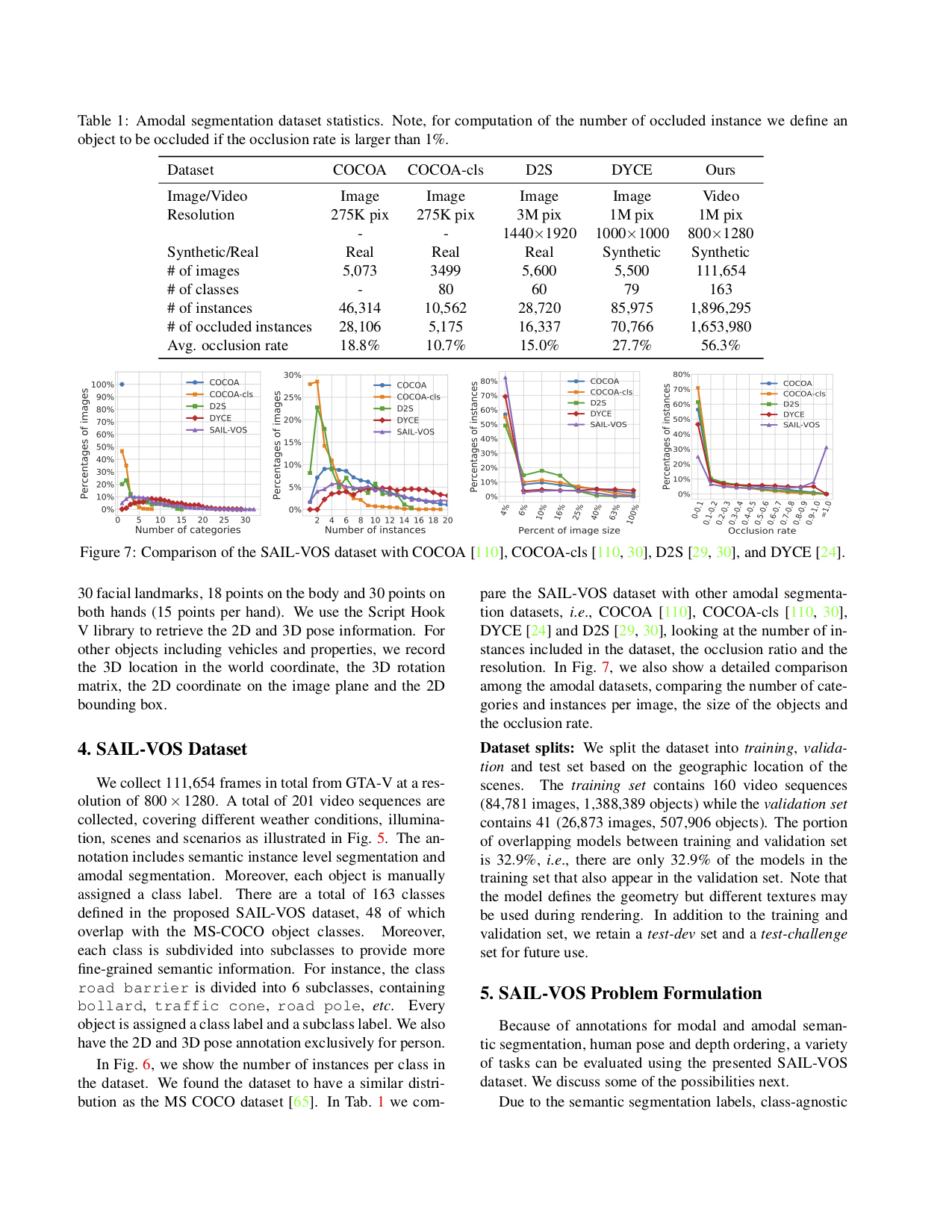
Please see the following table for comparison of statistics with the existing amodal datasets, COCOA, COCOA-cls, D2S and DYCE.
By downloading the data you agree to the following terms:
1. You will use the data only for non-commercial research and educational purposes. Commercial use is prohibited.
2. You will NOT distribute the data.
3. You buy Grand Theft Auto V.
@inproceedings{HuCVPR2019,
author = {Y.-T. Hu and H.-S. Chen and K. Hui and J.-B. Huang and A.~G. Schwing},
title = { {SAIL-VOS: Semantic Amodal Instance Level Video Object Segmentation -- A Synthetic Dataset and Baselines} },
booktitle = {Proc. CVPR},
year = {2019},
}